
프론트엔드 면접 준비를 위한 질문 리스트 정리
Front-end
아래질문 리스트를 기반으로 면접 질문 & 답변 목록을 작성할 예정이고, 지속적으로 보충 or 보수할 계획입니다.
- 업데이트 날짜
- 2020-10-26
- 2021-07-26
질문 목록
- 브라우저의 렌더링 과정에 대해서 상세하게 설명해달라
- DOM을 건드리는 방식과 아닌 방식들의 차이는 무엇인가
- CORS(Cross-Origin Resource Sharing)는 무엇인가 왜 이러한 방법이 정의 되었으며, 본인이 코드를 작성하면서 CORS와 관련하여서 경험하였던 이슈는 무엇인가
- 라이브러리와 프레임워크에 대해서 설명해달라
- 프로세스와 스레드의 차이는 무엇인가
- CSR과 SSR의 차이
- 가비지컬렉터의 역할은? 어떻게 동작하나요?
- 크로스 브라우징이란 무엇인가요?
- 우아한 퇴보와 점진적 향상은 무엇인가요?
- UA문자열을 이용하여 기능 검출(feature detection)과 기능 추론(feature inference)의 차이점을 설명 하시오
- FOUC (Flash Of Unstyled Content) 가 무엇이며 어떻게 해결할수 있나요?
- 코드 의존성과 DRY원칙
번외
- 호스팅
- IP
- DNS
- HTTP
- ISP
- 클라이언트 to 클라이언트의 전체 흐름
1. 브라우저의 렌더링 과정에 대해서 상세하게 설명해달라
렌더링 이란 서버로부터 HTML 파일을 받아 브라우저에 뿌려주는 과정 이고, 중요 렌더링 경로 (Critical Rendering Path)이란 브라우저에서 화면이 그려지기까지의 주요한 과정으로, 브라우저가 HTML, CSS, Javascipt를 화면에 픽셀로 변화하는 일련의 단계 를 말하며 이를 최적화하는 것은 렌더링 성능을 향상시킵니다.
간략하게
- HTML 마크업을 Parsing(처리)하여 DOM 트리를 빌드한다. (“무엇을” 그릴지 결정한다.) (DOM 파싱)
- CSS Parsing(처리)하여 CSSOM 트리를 빌드한다. (“어떻게” 그릴지 결정한다.) (CSS 파싱)
- DOM 및 CSSOM 을 결합하여 렌더링 트리를 형성한다. (“화면에 그려질 것만” 결정) (Combination)
- 렌더링 트리에서 레이아웃을 실행하여 각 노드의 기하학적 형태를 계산한다. (“Box-Model” 을 생성한다.) (Layout)
- 개별 노드를 화면에 페인트한다.(or 래스터화) (Painting)
- 렌더링이 완료된 상태에서 사용자의 인터랙션에 의해 화면의 일부 영역이 변경된다면,
리플로우또는리페인트가 발생한다.
개략적인 과정 은 아래와 같다.
웹 페이지 또는 어플리케이션에 대한 요청은 HTML 요청으로 시작됩니다.
서버는 응답 헤더 또는 데이터로 HTML을 반환합니다.
브라우저는 HTML을 분석하고 수신된 bytes를 DOM 트리로 변환하기 시작합니다.
브라우저는 스타일시트, 스크립트 또는 포함된 이미지 참조인 외부 자원에 대한 링크를 찾을때마다 요청을 시작합니다.
불러온 Assets를 다룰 때까지 나머지 HTML을 분석하는 작업하는 일부 요청은 중단되며 차단됩니다.
파싱은 CSS file을 만났을때도 계속되지만 특히
async또는defer속성이 없는<script>태그를 만났을 경우에는 렌더링을 멈추고 HTML 파싱을 중단합니다. 비록 브라우저의 프리로드(preload) 스캐너가 이 과정을 가속화하지만 과도한 스크립트는 여전히 심각한 병목현상이 될 수 있습니다.메인 스레드가 HTML, CSS를 분석하는 동안 Preload scanner는 스크립트와 이미지를 검색할 것이고 다운로드 받기 시작할 것입니다. 스크립트가 DOM 트리 구성 프로세스를 막지 않도록 보장하기 위해, 만약 Javascript 파싱 또는 실행 순서가 중요하지 않다면
async또는defer속성을 추가해야 합니다.CSS를 받기 위해 대기하는 것은 HTML 분석 또는 다운로딩은 막지 않지만 Javascript는 종종 HTML 요소에서 CSS 속성을 조회하는데 영향을 끼치기 때문에 막습니다.
브라우저는 CSSOM 구축 작업이 끝날때까지 요청을 만들고 DOM을 생성하는 HTML을 계속해서 분석합니다.
DOM과 CSSOM이 완료되면 브라우저는 렌더 트리를 생성하고 보여지는 컨텐츠를 위해 스타일을 계산합니다. (Layout)
- 레이아웃 은 너비, 높이 그리고 렌더 트리 안에서 모든 노드들의 위치를 결정하는 과정으로, 각 노드의 위치를 계산하기 위해 렌더 트리에서 레이아웃을 작동시키는 것입니다.
- 페이지 안에서 각 오브젝트의 크기와 위치에 대한 결정도 추가됩니다. 리플로우 는 페이지의 특정 부분 또는 전체 도큐먼트의 어떤 연속적인 크기와 위치에 대한 결정입니다.
렌더트리가 완료된 후 모든 렌더 트리 요소들에 대한 위치와 크기가 정의된 레이아웃이 만들어집니다. 일단 완료되면 레이지는 렌더링되거나 또는 화면에 ‘그려집니다(painted)’.
2. DOM을 건드리는 방식과 아닌 방식들의 차이
이 질문에 대한 핵심 or 예상 의도
모던 js 프레임워크의 가상돔 (Virtual Dom)에 대한 질문
직접 DOM을 건드리는 경우 DOM의 구조를 파악하고 있어야하며, 클래스명이다 태그명이 바뀌는 경우 다시 DOM을 변경해야한다.
Angular의 경우 view와 model을 연결시키는 바인딩 작업이 있고 변화 감지를 통해서 상태를 보고 있다가 업데이트 되는 방식이다. React와 Vue의 경우 가상 DOM이 있고, 가상 DOM이 실제 DOM과 비교하여 state가 변화되었는지 감지 한다.
3. CORS(Cross-Origin Resource Sharing)
1) 정의
교차 출처 자원 공유(Cross-Origin Resource Sharing)의 줄임말로, 여기서 말하는 오리진이란 도메인(domain)을 naver.com 라고 한다면 오리진(origin)은 https://www.naver.com/PORT 으로 차이는 프로토콜과 포트번호의 포함 여부이다.
__특정 오리진에서 작동하고 있는 웹 어플리케이션이 다른 오리진 서버로이 엑세스를 오리진 사이의 HTTP 요청에 허가를 할 수 있는 체계__를 말한다.
Cross-Origin Resource Sharing 표준은 웹 브라우저가 사용하는 정보를 읽을 수 있도록 허가된 출처 집합을 서버에게 알려주도록 허용하는 특정 HTTP 헤더를 추가함으로써 동작한다.
| HTTP Header | Description |
|---|---|
| Access-Control-Allow-Origin | 접근 가능한 url 설정 |
| Access-Control-Allow-Credentials | 접근 가능한 쿠키 설정 |
| Access-Control-Allow-Headers | 접근 가능한 헤더 설정 |
| Access-Control-Allow-Methods | 접근 가능한 http method 설정 |

2) 목적
- Same-Origin Policy
- 웹 시큐리티의 중요한 정책 중 하나로 Same-Origin Policy 가 있다.
- 이는 오리진 사이의 리소스 공유 제한을 둬 아래와 같은 위험을 막고자 함
- XSS (Cross Site Scripting)
- CSRF (Cross-Site Request Forgeries)
- XSS
- 공격자가 악성 스크립트를 신뢰할 수 있는 웹사이트에 삽입하는 방법
- 유저가 웹 사이트에 접속하는 것으로 정상적이지 않은 요청이 클라이언트에서 실행되는 것
- Cookie 내 Session 정보를 탈취 당하는 등의 예
- 종류
- Stored XSS: 보호되지 않고 검수되지 않은 사용자 입력으로 인한 취약점(데이터 베이스에 직접 저장되어 다른 사용자에게 표시됨)
- Reflected XSS: 웹 페이지에서 직접 사용되는 URL의 비보안에 의해 발생하는 취약점
- DOM based XSS: 웹페이지에서 직접 사용되는 URL의 비보안에 의해 발생한 취약점이라는 점에서 reflected XSS와 비슷하지만 DOM based XSS는 서버측으로 이동하지 않는다.
- CSRF
- 웹 어플리케이션의 유저가 의도하지 않은 처리를 웹 어플리케이션에서 실행되는 것
- 악의적인 웹사이트, 전자 메일, 블로그, 인스턴트 메시지 또는 프로그램으로 인해 사용자의 웹 브라우저가 사용자가 인증 된 다른 신뢰할 수 있는 사이트에서 원치 않는 작업을 수행 할 때 발생하는 공격 유형이다.
- 접근 권한이 있는 사용자만이 접근할 수 있는 요청이 멋대로 실행되는 등의 예
- 이 취약점은 브라우저가 세션 쿠키, IP주소 또는 각 요청과 유사한 인증 리소스를 자동으로 보내는 경우에 발생 할 수 있다.
3) CORS와 관련 경험 또는 이슈
REST API 서버 와 Web 서버 의 분리로 CORS를 해결해야 했으며 REST API 서버에 Role-based 구조를 띄고 있어 리소스 서버에 접근하기 전에 권한 검증을 위해 Preflight Request 를 구현했었음
Preflight Request 는 실제 요청 전에 인증 헤더를 전송해 서버의 접근 허용 여부를 미리 체크하는 테스트 요청으로, 서버 측에서는 브라우저가 해당 도메인에서 CORS를 허용하는지 알아보기 위해 preflight 요청을 보내는데, HTTP OPTION 메서드를 사용하며 Access-Control-Request-* 형태의 헤더로 전송한다.
이는 브라우저가 강제하며 HTTP OPTION 요청 메서드를 이용해 서버로부터 지원 중인 메서드들을 내려 받은 뒤, 서버에서 approval(승인) 시에 실제 HTTP 요청 메서드를 이용해 실제 요청을 전송하는 것이다.
개발시 참고했던 링크: Understanding Cross-Origin Resource Sharing
4. 라이브러리와 프레임워크에 대해서 설명해달라
라이브러리와 프레임워크의 차이는 자유도의 차이 인것 같다. 프레임워크는 짜여진 패턴이나 틀 기반에서 내가 코딩을 하는 것이고, 라이브러리는 내가 가져다 사용해서 자유롭게 사용하는 방식이다.
1) 라이브러리
라이브러리는 단순 활용가능한 도구들의 집합을 말합니다
즉, 개발자가 만든 클래스에서 호출하여 사용, 클래스들의 나열로 필요한 클래스를 불러서 사용하는 방식을 취하고 있습니다.
2) 프레임워크
뼈대나 기반구조를 뜻하고, 제어의 역전 개념이 적용된 대표적인 기술입니다
소프트웨어에서의 프레임워크는 ‘소프트웨어의 특정 문제를 해결하기 위해서 상호 협력하는 클래스와 인터페이스의 집합’ 이라 할 수 있으며, 완성된 어플리케이션이 아닌 프로그래머가 완성시키는 작업을 해야합니다. 객체 지향 개발을 하게 되면서 통합성, 일관성의 부족이 발생되는 문제를 해결할 방법중 하나라고 할 수 있습니다.
3) 차이
라이브러리와 프레임워크의 차이는 제어 흐름에 대한 주도성이 누구에게/어디에 있는가에 있습니다. 즉, 어플리케이션의 Flow(흐름)를 누가 쥐고 있느냐에 달려 있습니다
프레임워크는 전체적인 흐름을 스스로가 쥐고 있으며 사용자는 그 안에서 필요한 코드를 짜 넣으며 반면에 라이브러리는 사용자가 전체적인 흐름을 만들며 라이브러리를 가져다 쓰는 것이라고 할 수 있습니다. 다시 말해, 라이브러리는 라이브러리를 가져다가 사용하고 호출하는 측에 전적으로 주도성이 있으며 프레임워크는 그 틀안에 이미 제어 흐름에 대한 주도성이 내재(내포)하고 있습니다.
프레임워크는 가져다가 사용한다기보다는 거기에 들어가서 사용한다는 느낌/관점으로 접근할 수 있습니다.
5. (OS) 프로세스와 스레드의 차이
이 질문에 대한 핵심
운영체제에서 작업을 실행할때 자원을 할당하는 단위를 알고 있느냐와 프로그램을 멀티 쓰레드를 구현할때 장/단점을 알고 있느냐에 대한 질문 이다.
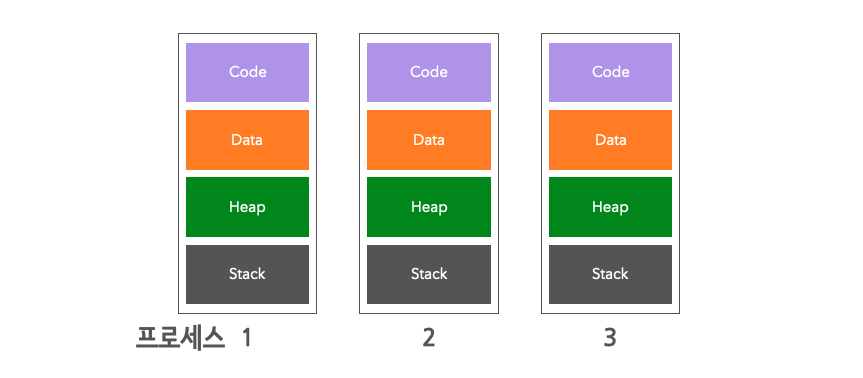
1) 프로세스 (Process)
컴퓨터에서 연속적으로 실행되고 있는 프로그램
- 프로그램 이란 실행 가능한 명령어의 집합으로, 여기서 얘기하는 프로그램이란 “디스크에 저장된 실행 가능한 명령어의 집합인지의 여부” 라고 말할 수 있다.
- 프로그램과 프로세스의 관계를 OOP (객체 지향 프로그래밍)의 클래스와 인스턴스 와 빗대어 예를 들면, 1개의 클래스에서 여러 인스턴스가 생성되듯이 1개의 프로그램에서 여러 프로세스가 생성되고 동시에 존재 가능.
- “메모장” 이라는
프로그램은 하나이지만,여러개의 메모장 (각 메모장 프로그램의 프로세스)이 실행될 수 있으며 동시에 존재 가능 - 커널 메모리 안에서 관리되는 PCB(Process Control Block) 정보 외에 유저가 사용하는 메모리 공간상의 프로세스 정보는 아래와 같다.
- Code: 프로그램의 실제 코드 저장
- Data: 프로세스가 실행될째 정의된 전역 변수. Static 변수들을 저장
- Heap: 프로세스 런타임 중 동적할당 변수들을 저장
- Stack: 함수 실행 등의 서브루틴 정보 저장
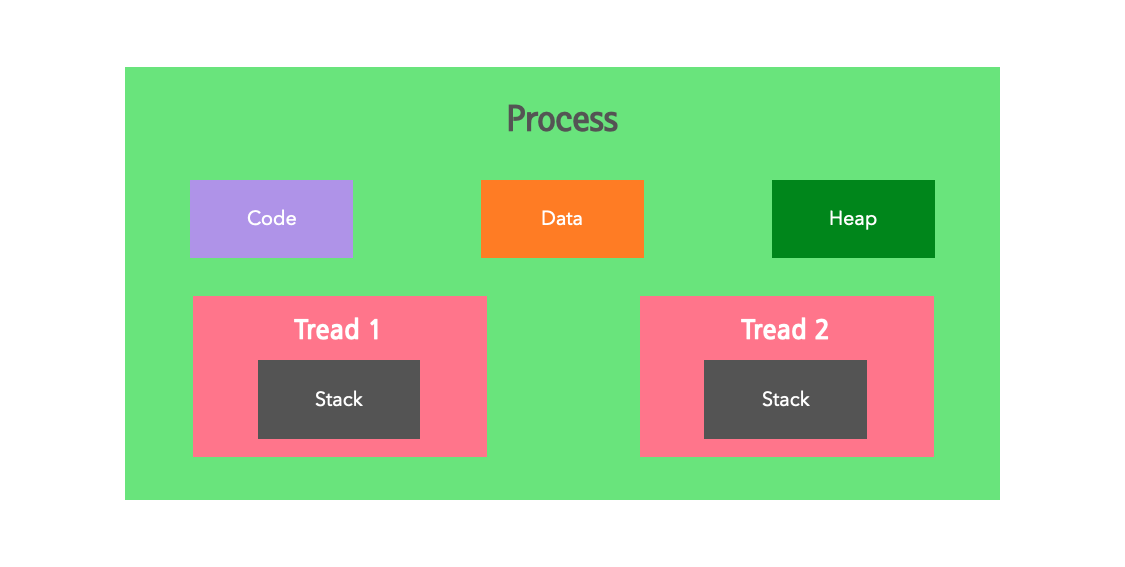
2) 쓰레드 (Tread)
한 프로세스 내에서 동작되는 여러 실행의 흐름
- 프로세스가 할당 받은 자원 (주소 공간이나 자원)을 이용하는 실행의 단위
- 운영체제적으로는 한 프로세스 안의 스레드들은 스택(Stack)을 제외한 프로세스의 나머지 공간(Code, Data, Heap)과 시스템 자원을 공유
- 한 스레드가 프로세스 자원을 변경하면, 다른 스레드도 그 변경 결과를 즉시 반영한다.
3) 프로세스와 쓰레드의 차이
프로세스는 운영체제로부터 독립된 시간, 공간 자원을 할당 받아 실행된다는 점이고, 스레드는 한 프로세스 내에서 많은 자원을 공유하면서 병렬적으로(Concurrently) 실행된다는 것이다. 다른 차이는 모두 이 근본적인 차이에서 비롯된다.
- 스레드는 프로세스 보다 독립적이다.
- 자원의 할당과 공유 측면에서, 스레드는 프로세스의 하위 집합으로 여러 스레드가 동일 프로세스의 자원을 공유하지만 프로세스는 보유한 자원에 대한 별개의 주소 공간을 갖고 공유해야하며 스레드는 이 주소 공간을 공유한다.
- 프로세스간 통신은 스레드간 통신보다 어렵다.
- 프로그램의 안정성 측면에서는 스레드는 단순히 공유 변수의 수정만으로도 스레드간 통신을 구현할 수 있으며 프로세스는 OS가 제공하는 IPC 메커니즘을 통해서만 통신할 수 있으며 시스템에 의해 관리된다. 다만, 상대적으로 프로세스가 나을 수 있다.
- Context Switch 측면에서도, 프로세스보다 스레드가 “일반적으로” 더 빠르고 자원소모가 적다.
- 프로세스는 Switch 될때 Context를 PCB 등에 저장하는 등 오버헤드가 발생하나 스레드는 상대적으로 부하가 적다.
- 그러나 OS, 배포버전 그리고 프로세스의 지원 환경에 따라 이 점은 달라질 수 있다.
| 차이 | 프로세스 | 스레드 |
|---|---|---|
| 지원 할당 여부 | 실행 시마다 새로운 자원 할당 | 동일 프로세스 내 자원을 공유 |
| 자원 공유 여부 | 일반적으론 자원 공유 하지 않으나 같은 프로그램의 경우 코드를 공유 | 동일 프로세스 내 스레드들은 스택을 제외한 자원을 공유 |
| 독립성 여부 | 일반적으로 독립적 | 프로세스 내 하위 집합 |
| 주소 소유 여부 | 별개의 주소 공간을 갖음 | 주소 공간을 공유 |
| 통신 여부 | 오직 시스템이 제공하는 IPC 방법으로만 통신 | 공유 변수 수정 등 자유롭게 동일 프로세스 내 타 스레드와 소통 |
| Context Switch | 일반적으로 프로세스 보다 스레드의 Context Switching이 더 빠를 수 있음 | OS, 배포버전 또는 프로세스 내 환경에 따라 유동적임 |
6. CSR과 SSR의 차이
1) SSR (Server-Side Rendering, 서버 측 렌더링)
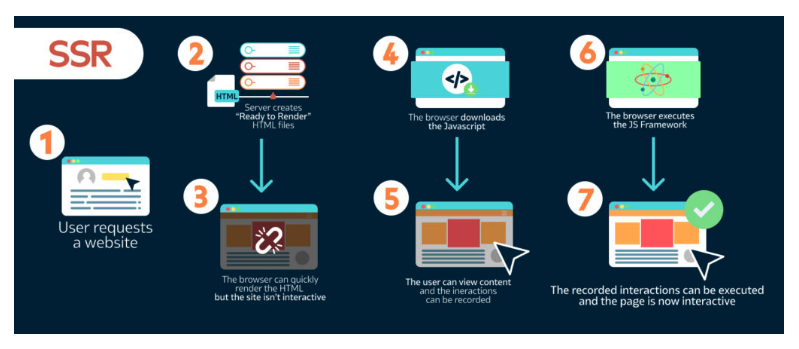
클라이언트 측 또는 유니버설 앱을 서버의 HTML로 렌더링합니다.
서버 렌더링은 탐색에 대한 응답으로 서버의 페이지에 대한 전체 HTML을 생성합니다. 이렇게 하면 브라우저에서 응답을 받기 전에 처리되므로 클라이언트에서 데이터 가져 오기 및 템플릿 작성에 대한 추가 왕복이 발생하지 않습니다.
2) CSR (Client-Side Rendering, 클라이언트 측 렌더링)
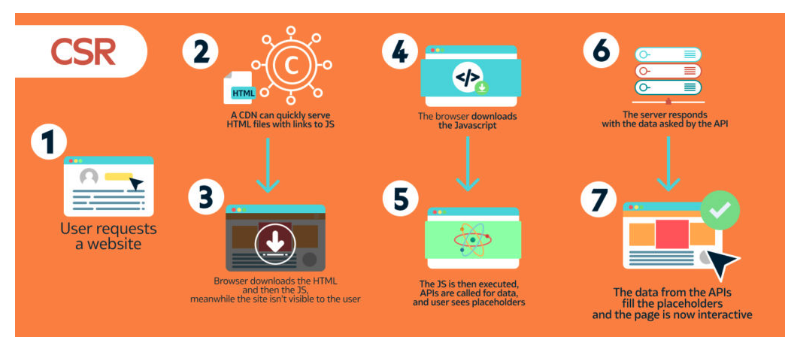
브라우저에서 애플리케이션을 렌더링합니다. 일반적으로 DOM을 사용합니다.
클라이언트 측 렌더링 (CSR)은 JavaScript를 사용하여 브라우저에서 페이지를 직접 렌더링하는 것을 의미합니다. 모든 로직, 데이터 가져오기, 템플릿 및 라우팅은 서버가 아닌 클라이언트에서 처리됩니다.
3) CSR SSR 장단점

4) CSR과 SSR의 차이
대표적으로, 초기 View 로딩 속도, SEO 문제, 보안 문제가 있다.
| SSR | CSR | |
|---|---|---|
| 초기 View 로딩 속도 | CSR에 비해 렌더링 해야하는 파일이 적어 초기 View 로딩 속도가 빠름. | 브라우저에서 페이지를 직접 렌더링해야 하므로 초기에는 오래 걸림. |
| SEO | 페이지에 대한 meta 정보가 렌더링시 이미 포함되어 있기 때문에 크롤러봇에서 데이터를 수집해가는데 용이함. | 렌더링시 JS 파싱, 로딩 및 실행 순서 때문에 크롤러봇이 데이터를 수집하는데 어려움이 있음. |
| 보안 문제 | 사용자에 대한 정보를 서버측에서 Session으로 관리 | 사용자에 대한 정보를 LocalStorage나 Cookie에서 관리해 XSS 공격에 취약함 |
5) 정리
- SSR 방식의 경우, 초기 로딩속도가 빠르고, SEO 측면에서 유리하지만
- View 변경시 서버에 계속 새로운 HTML 파일을 요청해야 하므로 서버에 부담이 큼
- CSR 방식의 경우, 초기 로딩속도는 느리지만 그 다음 페이지 이동 및 처리에 있어 필요한 데이터만 요청하면 되므로 서버에 부담이 적고, 빠르게 처리할 수 있으나
- SEO 측면에서 Google 크롤러봇을 제외하곤 Javascript를 실행시키지 못해 데이터 수집하는데 어려움이 있음
6) SPA + SSR ?
일단 서버와 클라이언트가 Node.js 라면 가능하다 (Isomorphic Javascript). 즉, 서버와 클라이언트가 동일한 코드로 동작한다는 의미로, React의 경우 Next.js와 같이 React SSR 라이브러리를 이용해서도 구현할 수 있으며 Vue.js의 경우 Nuxt.js를 이용해 구현할 수 있다.
7. 가비지컬렉터의 역할은? 어떻게 동작하나요?
메모리 할당을 추적하고 할당된 메모리 영역이 필요하지 않은 영역일 경우를 판단해서 회수하는 것.
자바스크립트에서 변수는 직접적으로 참조 값(문자열, 객체, 배열 등)을 담고 있지 않고, 해당 값을 메모리 상에 저장 된다. 그래서 참조 값을 생성하고나서 더이상 참조할 것이 없거나 비어졌을 때 가비지 컬렉터가 동작해서 메모리가 반환됨. (메모리를 다시 재사용할 수 있는 상태가 된다)
8. 크로스 브라우징이 무엇인가요?
크로스 브라우징은 웹 표준에 따라 서로 다른 OS 또는 플랫폼에 대응하는 것을 말한다. 브라우저별 렌더링 엔진이 다른 상황 등 어떠한 상황 속에서도 문제 없이 동작하게 하는 것을 목표로 한다. 프론트엔드 개발자는 여러가지 전략을 세울 수가 있는데, feature detection(기능 탐지)을 사용해서 해당 기능이 해당 브라우저에 있는지를 확인하는 방법을 사용할 수도 있다. 특히 한 쪽 환경에 최적화를 하는 것 보다, 전체적인 웹 표준을 지키는 데에 노력해야 한다.
1) 적용 기능의 지원 브라우저 파악 또는 Tool 사용
caniuse 사이트에서 스펙 조회 또는 크로스 브라우저 테스트 툴 사용 (BrowserStack, lambdaTest, Experitest)
2) 모든 환경에서 지원해야 한다면 라이브러리를 사용하자
대중적인 라이브러리는 호환성 이슈를 해결하기 위한 좋은 전략이다. ( ex) jQuery, underscore.js extJS, HTML5 polypill 라이브러리 )
직접 구현시 ‘기능 탐지’를 이용하자 (feature detection!)
1 | if (isIE) { |
3) 브라우저 표준에 맞게 스타일(CSS) 지원하기
Reset CSS 또는 Normalize.css를 사용합니다.
아직 웹 표준이 안된 CSS 기능을 지원해주기 위해 각 브라우저들의 엔진을 벤더 프리픽스(Vender Prefix) 수동으로 또는 autoprefixer 를 자동으로 추가하자.
4) Reset.css과 Normalize.css
reset.css는 기본적으로 제공되는 브라우저 스타일 전부를 제거 하기 위해 사용된다. reset.css가 적용되면 <H1>~<H6>, <p>, <strong>, <em> 등 과 같은 표준 요소는 완전히 똑같이 보이며 브라우저가 제공하는 기본적인 styling 이 전혀 없다.
normalize.css는 브라우저 간 일관된 스타일링을 목표로 한다. <H1>~<H6>과 같은 요소는 브라우저간에 일관된 방식으로 굵게 표시됩니다. 추가적인 디자인에 필요한 style 만 CSS 로 작성해주면 된다.
즉, normalize.css는 모든 것을 “해제”하기보다는 유용한 기본값을 보존하는 것이다. 예를 들어, sup 또는 sub 와 같은 요소는 normalize.css가 적용된 후 바로 기대하는 스타일을 보여준다. 반면 reset.css를 포함하면 시각적으로 일반 텍스트와 구별 할 수 없다. 또한 normalize.css 는 reset.css 보다 넓은 범위를 가지고 있으며 HTML5 요소의 표시 설정, 양식 요소의 글꼴 상속 부족, pre-font 크기 렌더링 수정, IE9 의 SVG 오버플로 및 iOS 의 버튼 스타일링 버그 등에 대한 이슈를 해결해준다.
9. 우아한 퇴보와 점진적 향상은 무엇인가요
사용자가 항상 최신 기술을 사용할 수 있는 환경에서 서비스를 사용하지는 않는다. 특히 웹사이트를 만들 때는 최신 브라우저와 구식 브라우저를 모두 신경써야 한다. 점진적 향상법과 우아한 성능저하법은 최신과 구식에 대응하기 위한 방법을 말한다. (참고)
점진적 향상법은 기본적으로 구식 기술 환경에서 동작할 수 있는 기능을 구현하고, 최신 기술을 사용할 수 있는 환경에서는 더 나은 사용자 경험을 제공할 수 있는 최신 기술을 제공하는 방법이다. 즉, 구식 환경에서도 충분히 서비스를 사용할 수 있고, 최신 환경이라면 더 나은 기능들을 사용할 수 있도록 만드는 것이다. 구식 브라우저를 사용하는 사용자에게 100만큼의 기능을 제공하고, 최신 브라우저를 사용하는 사용자에게는 130정도의 기능을 제공하도록 웹사이트를 만든다고 보면 된다.
우아한 성능저하법은 점진적 향상법과 반대이다. 이는 최신 기술을 기반으로 기능을 구현한 뒤, 구형 기술에 기반한 환경에서도 유사하게 동작하도록 만드는 방법이다. 최신 브라우저에서는 100만큼의 기능을 제공하고, 구식 브라우저에서는 50정도의 기능만을 제공하게 웹사이트를 만드는 것이다. img 태그에 alt 속성을 지정함으로써 이미지를 보여주지 못하는 환경에서 이미지를 텍스트로 대체하는 것이 대표적인 예시다.
요약
우아한 퇴보 란 최신 브라우저를 위한 어플리케이션을 구축하는 동시에 그것이 구형 브라우저에서도 계속 작동하도록 하는 구축방법이고,
점진적 향상 는 기본 수준의 사용자 환경에 대한 응용 프로그램을 구축하지만 브라우저가 이를 지원할 경우 기능을 강화하는 방법입니다.
10. UA문자열을 이용하여 기능 검출(feature detection)과 기능 추론(feature inference)의 차이점을 설명 하시오
UA 문자열
- User Agent String의 약어로 브라우저에서 어떤 사이트에 접속하면 서버는 요청한 브라우저가 어떤 브라우저인지에 따라 그에 맞게 결과를 보여준다. 예를들어 내가 Chrome으로 Naver를 들어가면 Naver 서버에는 User Agent로 아래 값을 받게 될 것이다.
- 이러한 정보는 광고 솔루션에서 유저를 트래킹할 때도 유용하고, 특정 브라우저에서 사이트 이용을 제한할 때도 사용 할 수 있다.
1 | "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.89 Safari/537.36"; |
기능 검출(feature detection)
브라우저가 환경이 특정 기능을 제공하거나 제공하지 않을 수있는 단서를 프로그래밍 방식으로 테스트하여 런타임 환경 간의 차이를 처리하기 위해 웹 개발에 사용되는 기술
스크립트가 호출하는 기능을 사용자의 브라우저가 지원하는지 체크하는 것을 말한다. 다음은 브라우저가 GPS를 지원하는지 확인하는 코드다.
1 | if ("geolocation" in navigator) { |
기능 추론(feature inference)
feature detection 처럼 기능을 확인하는 것은 똑같지만, A 라는 기능이 있을 때 B 도 있을거라고 추론하기 때문에 특정 상황이 아니면 사용 하지 않는 기법이다. 기능 추론도 기능 검출처럼 브라우저가 특정 기능을 지원하는지 체크하는 것이다. 하지만 ‘A기능을 지원하면 B기능도 지원할 것이다.’라는 추론이 바탕이 된다. 별로 좋지 않은 방법이다.
Case
UA 문자열을 가지고 해당 유저의 환경에 대한 정보를 모두 가져 올 수 있는것을 활용해 두 패턴에 대해 예시를 들어 설명 해보자면 호환성 문제로 인해 Internet Explorer 지원을 하지 않기로 한 웹 서비스가 있다고 해보자. 그럼 이때 FE 개발자는 UA를 가지고 Internet Explorer 를 감지 할 수 있을 것이다.
1 | if (navigator.userAgent == "Chrome") { |
두 방식을 pseudo code 로 구현한 내용이다. alert()으로 알려주는 방식은 IE에서 잘 동작해서 경고를 띄워주겠지만(IE에서 페이지를 이동 해 주는 메서드가 없다는 전제) Feature inference 방식으로 작성한 history.push()는 IE에서 지원하지 않기 때문에 작동하지 않을 가능성이 크다.둘의 차이는 얼마나 추론과 탐지를 하느냐인데, 후자인 Feature inference는 특정 상황이 아니라면 사용하지 말아야 한다.
11. FOUC (Flash Of Unstyled Content) 가 무엇이며 어떻게 해결할수 있나요?
FOUC란 무엇인가
FOUC(Flash of Unstyled Content)는 브라우저로 웹문서에 접근했을때, 미처 CSS의 스타일이 모두 적용되지 못한 상태에서 화면이 표시되어 발생하는 화면 깜박임, 스타일의 적용 전과 적용 후가 그대로 화면에 노출된 상태로 변경되는 현상등을 일컫는다. 이 현상은 특히 IE(Internet Explorer) 브라우저에서 확인되는데 최신의 IE11에서도 여전히 발생되는 문제이다. 이는 해당 웹문서의 사용자 경험을 떨어뜨리는 요인으로 작용한다.
FOUC 원인
FOUC가 발생하는 주된 원인은 브라우저의 동작 방식과 연관이 있다.
- 브라우저는 마크업에 참조된 모든 부수적인 파일들을 모아 즉시 DOM(Document Object Model)을 생성
- 가장 빠르게 분석할 수 있는 글의 내용부분을 화면에 표시
- 화면에 표시된 내용을 선언된 마크업의 순서에 따라 스타일을 적용하고 스크립트를 실행
최근의 웹문서들은 여러 개의 CSS 파일을 참조하고 DOM 구조를 변경하므로 이는 더욱 빈번하게 발생하고 있다.
- 웹문서들은 종종 프린터와 무선 장치를 위한 CSS 규칙으로 브라우저 화면 이외의 다른 미디어에 대한 스타일 참조를 포함한다.
- 웹문서는 @import로 스타일 파일을 가져오고, 다른 CSS를 참조할 수 있다.
- 온라인 광고와 동영상과 검색 엔진같은 다른 곳에서 삽입된 콘텐츠는 종종 코드 블록 내에서 자신의 스타일 규칙을 구술한다.
- 웹 문서가 모두 불러와진 후 자바스크립트를 이용해 DOM 구조를 변경한다.
무엇보다도 최근에 많이 사용되고 있는 웹폰트의 경우에도 IE 브라우저에서는 FOUC를 유발해 매우 산만하고 아름답지 못한 경험을 선사한다.
FOUC 해결책
- FOUC를 최소화하기 위해서는 기본적으로
<head>요소안에 CSS를 링크하고, @import의 사용을 자제해야 한다. - 자바스크립트의 선언순서, 위치를 변경함으로써 극복 가능하거나, 매우 짧아질 수 있다.(성능을 위해
</body>요소 앞에 자바스크립트를 위치시키곤 하는데 이를<head>안으로 위치를 변경해 본다.) - FOUC를 유발하는 구역을 숨겼다가 문서의 스타일이나 스크립트가 모두 적용되면 보여준다.
FOUC를 유발하는 구역을 숨겼다가 다시 보여주는 방법을 아래에서 설명한다.
1 | <html class="no-js"> |
html 태그에 .no-js를 추가하고 head 태그에 스타일과 자바스크립트를 추가한다. 해당 자바스크립트는 브라우저의 자바스크립트가 활성화되어 있을 경우, html 태그의 클래스를 .js로 변경한다. 숨겨질 구역에 ID 값으로 fouc를 추가했다.
위와 같이 페이지 전체를 감싸는 영역을 지정하면 빈 페이지를 보여주다가 모든 리소스가 로드되면 페이지를 보여주게 된다.
12. 코드 의존성과 DRY원칙
어떤 스크립트는 다른 추가적인 스크립트를 필요로 하기도 한다. 이때 다른 스크립트에 의존하는 스크립트를 작성할 때 해당 스크립트에 의존성이 있다고 표현한다. jQuery를 활용하는 스크립트는 의존성이 있다고 할 수 있다. 이런 경우 주석을 통해 의존성을 명시하는 것이 좋다.
DRY원칙은 Don’t Repeat Yourself의 줄임말로, 소프트웨어 개발 원칙을 말한다. 한국어로는 중복배제라고 한다. 같은 작업을 수행하는 코드를 두 번 작성했다는 이를 코드 중복이라고 하는데, DRY원칙은 이러한 코드 중복을 지양하자는 원칙이다. 코드 중복의 반대 개념으로는 코드 재사용(Code reuse)이 있다. 코드 재사용은 같은 코드가 스크립트의 다른 곳에서 한 번 이상 사용되는 것을 말한다. 함수를 활용하는 것은 코드 재사용의 좋은 예로, 재사용 가능한 함수를 헬퍼 함수(Helper function)라고 한다. 코드 재사용을 권장하기 위해 개발자들은 작은 스크립트를 작성하는데, 이때문에 코드 재사용은 코드 사이에 더 많은 의존성을 만든다
번외
호스팅
호스팅(hosting)이란 서버 컴퓨터의 전체 또는 일정 공간을 이용할 수 있도록 임대해 주는 서비스이다. 즉, 호스팅 업체가 회사나 개인에게 항시 가동중인 서버를 임대 해 주고 그 대가를 받는 서비스가 호스팅이다. Web을 제공하는 회사들은 대부분 별도의 호스팅 서버를 운용하여 외부 요청에 응답한다. 즉, 24시간 꺼지지 않도록 해야하며 필요하다면 이중화구조로 장애 발생시에도 응답에 문제가 없도록 대처 할 수 있도록 구성해야 한다.
최근에 Twitch에서 스트리머들의 생방송을 본 적이 있는데, 이때에도 A 라는 스트리머가 방송을 종료하며 B 라는 스트리머에게 시청자들을 호스팅 한다는 개념이 등장한다. 쉽게 이해하기 위해서는 영어 단어 그대로 Host + ~ing 이므로 주최(Host)하다 로 이해할 수도 있을 것 같다.
IP
Internet Protocol의 준말로 송신 호스트와 수신 호스트가 패킷 교환 네트워크에서 정보를 주고받는 데 사용하는 정보 위주의 규약(프로토콜, Protocol)이며, OSI 네트워크 계층에서 호스트의 주소지정과 패킷 분할 및 조립 기능을 담당한다.
그냥 쉽게 데이터가 어떤 규약에 의해 주고받아지고, 이를 분해해서 보내고 조립해서 사용자에게 보여주는 규약이다. 그리고 이를 기반으로 한 IP 주소는 장치들이 서로의 위치를 인식하고 통신하기 위해 사용하는 번호이다. IP주소는 모든 네트워크를 지원하는 장비에 할당되어있다. 우리가 쓰는 스마트폰부터, 랩탑, 데스크탑, 심지어 애플워치나 인공지능 스피커까지 다양하게 있다.
DNS
위에서 설명한 IP 주소의 형태는 IPv4 기준으로 172.16.254.1 같은 표기법을 가지고 있는데, 사용자가 매번 이런 IP 주소를 외우기는 쉽지 않기 때문에 더 쉽게 IP 주소를 알아내개 위해 만든 것이 Domain이고 이를 관리하는 곳이 Domain Name Server(DNS)이다.
DNS의 주 기능은 특정 컴퓨터(또는 네트워크로 연결된 임의의 장치)의 주소를 찾기 위해, 사람이 이해하기 쉬운 도메인을 숫자로 된 식별 번호(IP 주소)로 변환해 준다. DNS에는 우리가 아는 KT나 LG유플러스를 시작으로, CloudFlare나 Google 도 DNS 를 가지고 있다. 우리가 흔히 사용하는 www.google.com 이나 www.naver.com 도 Domain으로 DNS에서 IP 주소로 변환된다.
당연히 이런 이름들은 중복되서는 안되기 때문에 DNS에서는 이를 조절해준다. 또한 서로 다른 DNS로 정보를 전달하는 시간때문에 DNS 등록 직후 바로 조회되지 않고 각 DNS 업데이트 주기에 맞추어 1~2일 정도 있다가 사용 가능해지기도 한다.
HTTP
간단하게 Request와 Response를 통해 이뤄지는 통신 구조로 두 서버끼리 연락할 때 그 방식을 정해놓은 규약이라고 보면 된다. 우리가 흔히 쓰는 GET, POST, DELETE, PATCH, PUT ··· 는 HTTP Request이고, 200 OK, 300 Rediredt, 404 Not Found 등은 HTTP Response의 종류이다.
또한 무상태 Stateless이기 때문에 단순히 통신만으로는 로그인 정보, 방문 횟수 등의 브라우저 정보를 저장할 수 없고 이를 위해서는 쿠키나 세션을 이용해야만 한다. HTTP 규약은 전통적으로 HTTP/1.x을 사용되었지만 TLS 추가, 속도 및 기능이 개선된 HTTP/2를 사용하는 것이(아마 나도모르게 사용하고 있겠지만) 여러모로 더 낫다.
ISP
SP(Internet service provider)는 인터넷에 접속하는 수단을 제공하는 주체를 가리키는 말이다.
쉽게 말해 Web(거미줄)을 물리적으로 만드는 곳이라고도 볼 수 있는데, 대륙간 통신이나 적도에서 극지방에 이르기까지 광섬유를 산넘고 바다건너 지하에다가 쭉 깔아두는 회사라고 보면 된다. 혹자는 위성 인터넷을 쓰면 되지 않느냐고하는데, 맞다. 위성 인터넷도 하나의 대안일 수 있지만 위성까지 왕복하는 거리가 광섬유로 연결하는 것보다 배이상 길기 때문에 지연시간도 거기에 정비례하게 되기 때문에 속도나 안정성 측면에서 광섬유로 연결하는것이 낫다.

ISP도 다 같은 ISP가 아니고 Tier 1, 2, 3으로 구분된 제공자로 구분된다. Tier 1은 주로 대륙간 트래픽 교환을 담당하고 Tier 2는 Tier 1과 3을 이어주는 중매및 피어링을 담당한다.(다른 ISP끼리 트래픽을 교환하는 것) 우리가 가장 가까이에서 볼 수 있는 Tier는 Tier 3으로 대한민국에서는 KT, Uplus 등이 이에 해당한다.
클라이언트 to 클라이언트의 전체 흐름
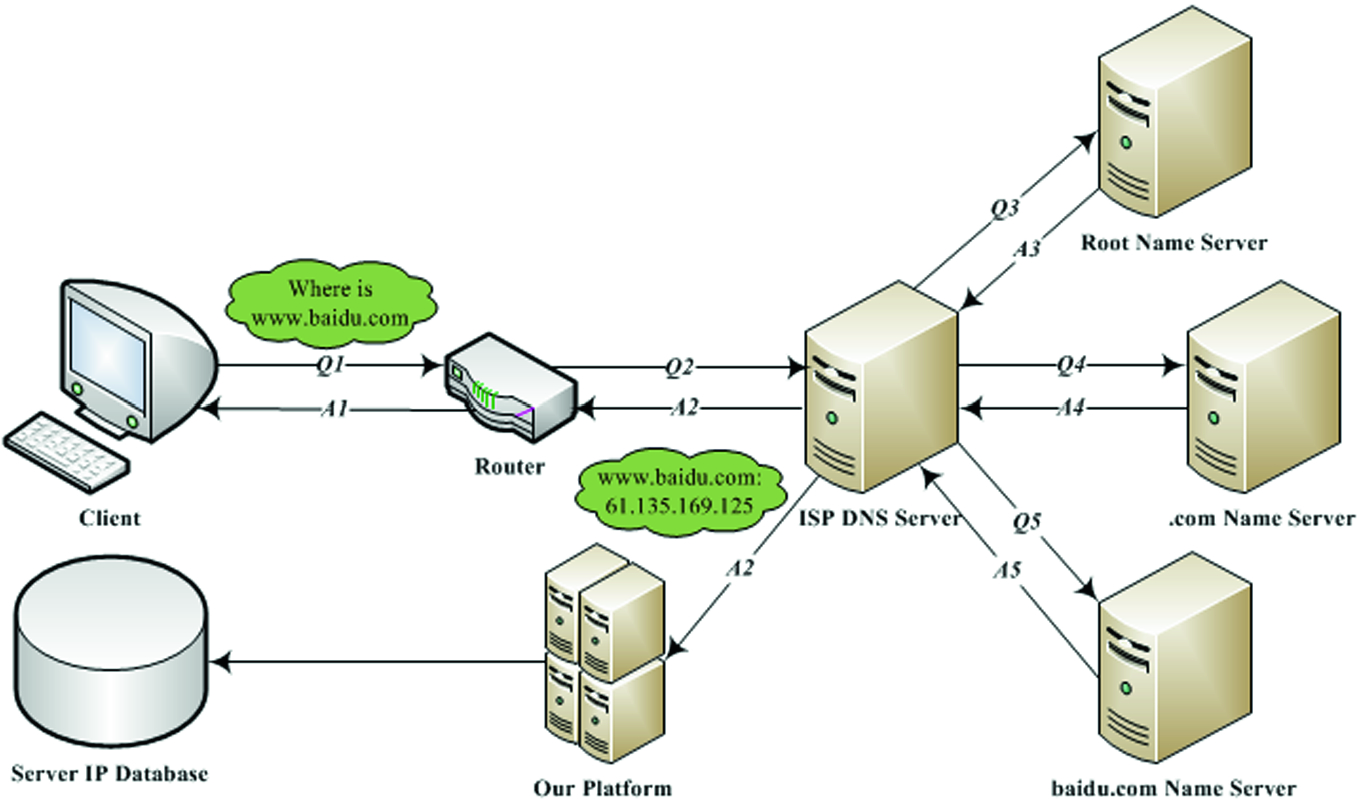
전체적인 흐름은 사용자가 특정 도메인 주소를 주소창에 입력하는 것부터 시작해서 요청한 도메인의 컨텐츠가 화면에 나오는 것까지를 다룬다.
다음은 www.google.com을 요청하는 것을 예시로 한다.
웹 서버로 요청
- 사용자는 주소창에 www.google.com을 입력한다.
- 브라우저는 해당 도메인을 HTTP 규약에 맞춰 데이터 패킷을 준비한다.
- 준비된 패킷은 랜선 혹은 AP를 통해 해당 지역의 Tier 3 ISP 까지 전달된다.
- 이때 클라이언트는 빠른 응답을 위해 Cache Server에 캐싱 해 놓은 결과가 있는지 먼저 확인하고 만약 캐시된 데이터가 있으면 더 진행하지 않고 이를 다시 클라이언트에 되돌려준다.
- ISP는 DNS를 겸하기도 하기 때문에 요청으로 들어온 www.google.com의 IP 주소를 확인한다.
- 만약 해당 DNS에 정보가 없다면 다른 DNS 서버에 해당 도메인이 있는지 확인한다.
216.58.220.142가 www.google.com 의 IP 주소임을 브라우저가 알게 된다.- 브라우저는 해당 IP 주소로 HTTP Request를 보낸다.
- Google의 WAS(Web Application Server)는 요청을 받아서 DB작업 필요하다면 이를 처리한다.
- 사용자 요청에 맞는 컨텐츠를 Status Code같은 내용과 함께 HTTP Response로 돌려 보낸다.
- 다시 수많은 Router들과 ISP를 거쳐 사용자의 브라우저에 컨텐츠가 도달한다.
웹 서버로부터 응답 받고 브라우저가 하는 일
- 처음 브라우저가 응답을 받으면, 브라우저가 가지고있는 파서를 이용해 HTML문서를 브라우저가 이해할 수 있는 DOM 트리 형식으로 파싱한다.
- CSS를 파싱하여 스타일 구조체의 형식으로 만든다. 이를 CSSOM이라고 한다.
- DOM과 CSSOM을 실제 화면에 표현하기 위한 데이터 구조인 렌더링 트리로 변환한다.
- 해당 렌더링 트리를 그리고 화면에 표시한다.
참조
- HTML 기초 - 3 (렌더링이란?)
- CORS(Cross-origin Resource Sharing)
- CORS 개념과 간단한 XSS ,CSRF 소개
- 프레임워크와 라이브러리의 차이점
- Process와 Thread의 차이
- 프로세스와 스레드의 차이
- [OS] 프로세스와 스레드의 차이
- A Closer Look at Client-Side & Server-Side Rendering
- 서버 사이드 렌더링(SSR)과 클라이언트 사이드 렌더링(CSR)
- SPA에서의 SSR과 CSR
- 웹 렌더링
- 프론트엔드 개발자 면접 질문(기술면접) 정리
- 기능이 제한된 브라우저의 페이지는 어떻게 처리하나요? 어떤 기술/프로세스를 사용하나요?
- 브라우저 별로 스타일이 다른 문제를 어떤 접근 방법으로 해결하나요?
- 개발자-인터뷰-문제-javascript-영역 [과학을 이해하는 개발자]
- 화면 깜빡임(FOUC) 문제해결
- Javascript 기초 - 별에서 온 그대, Web이 동작하는 방식 - samslow님 블로그